》》以下内容参考wikipedia。
https://en.wikipedia.org/wiki/Precision_and_recall

- 精确度 precision = (true positive)/(selected elements) = tp/(tp+fp) ,表示预测为正例的样本中,真正的正例所占的比例。
- 召回率 recall = (true positive)/(relevant elements) = tp/(tp+fn) ,表示被预测出的真正的正例,占真正的正例的比例。
注:实际任务中经常使用这两个基本指标的加权组合(即,F-measure,也称F-score),至于权值根据不同任务酌情使用。
经常使用的而是两者的调和平均数,即(其中p表示precision, r表示recall):
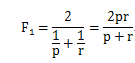
对于多分类(如N分类),可以看成是N分类,对N个类别的p,r,F1值的平均方法有两种:marco-(即宏平均),micro-(即微平均)。
macro-: 先分别计算出各类的指标,再取平均值。如macro_p= (p1+p2+...+pN)/N
micro-:先计算出所有类别的tp, fp等的平均值,再代入指标计算公式中求出结果。如micro_p= ave_tp/(ave_tp+ave_fp)
类似方法计算得 macro-r, micro-r
最后:
macro_f1 = 2*macro_p*macro_r / (macro_p+macro_r)
micro_f1 = 2*micro_p*micro_r / (micro_p+micro_r)
补充机器学习分类任务中其他指标:
- 准确率(accuracy)
其定义是: 对于给定的测试数据集,正确分类的样本数与总样本数之比。
accuracy = (true positive + true negative) / (tp + tn + fp + fn)
- 混淆矩阵(Confusion Matrix)
在机器学习领域,混淆矩阵(confusion matrix),又称为可能性表格或是错误矩阵。
例如:
实际值:8只cat, 6条dog, 13只rabbit
预测值:7只cat, 8条dog, 12只rabbit
则混淆矩阵为:
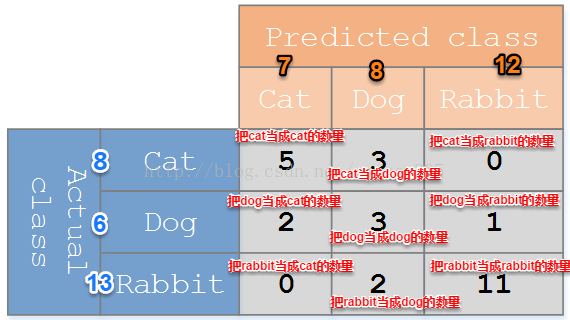
从上表中能看出:
Cat的召回率(recall): 5/8
Dog的召回率(recall): 3/6
Rabbit 的召回率(recall):11/13
Cat的精确率(precision): 5/7
Dog的精确率(precision): 3/8
Rabbit 的精确率(precision):11/12
上例参考自:http://blog.csdn.net/vesper305/article/details/44927047
- 对数损失(Log-Loss)
- 曲线下面积(AUC